

Data Lakehouse & Data Lake: Introduction
In big data, organizations constantly face the challenge of managing and analyzing vast data. As data volume, variety, and velocity grow, businesses must choose the exemplary architecture that effectively handles their significant data needs. How do you select the equitable architecture conferring to your data needs?
Overview of Data Lakehouse & Data Lake
Data lake vs. lakehouse
A data lake is a dynamic and centralized repository that houses and processes enormous amounts of structured and unstructured data of various scales.
Data lakes allow organizations to stockpile data from various sources, including social media, applications, sensors and more, without imposing overwhelming formatting requirements. This versatility of data lake permits organizations to retain data in its original state until required, warranting them to be ideal for machine learning, predictive analytics, and user profiling and to explore and develop insights as business needs evolve.
Data Lakehouse
A data lakehouse is a newer and more significant data storage architecture designed to address the constraints of the data lake and data warehouse, which combines the strengths of both data lakes and data warehouses, offering a unified platform for data storage, processing, and analysis.
In a data lakehouse, data is stored in its raw format within a data lake, similar to that in a traditional data lake. However, what sets a data lakehouse apart is its capability to apply schema enforcement and indexing on the data, akin to a data warehouse, as it’s ingested. This allows for efficient querying and analysis without requiring extensive data transformation before analysis.
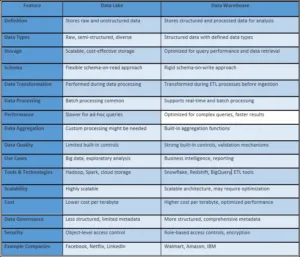
Comparing Data Lakehouse & Data Lake
Data Lakehouse vs. Data Lake
Data Ingestion:
In both a data lakehouse and a data lake, data ingestion involves accumulating and loading data from different sources into the respective storage repositories. However, these two architectures significantly differ in how data is ingested and managed.
In a conventional data lake, data ingestion is relatively straightforward and flexible. Data is ingested in its raw and unprocessed form, regardless of its structure or format. This raw data is then stored within the data lake, often using distributed file systems or object storage systems. A data lake’s primary focus is storing vast amounts of data with minimal upfront processing.
Data ingestion is more refined in a data lakehouse than in a traditional one. While maintaining the raw format, an additional layer is added for schema enforcement and indexing during ingestion.
This means that as data is ingested into the data lakehouse, some structure is imposed on the data to facilitate more efficient querying and analysis later on. This schema-on-read approach balances the flexibility of raw data storage and the performance optimization of structured data warehouses. If we take Airbnb, for example, to enhance their infrastructure, they upgraded to lighthouse architecture. Based on Apache Iceberg and Spark 3, their new stack helped them save more than 50% on compute resources and 40% on job elapsed time reduction in their data ingestion framework.
Data Governance:
Data governance can be challenging in a data lake due to the need for a more predefined structure and standardized metadata.
It may be ingested from diverse sources without strict controls, potentially leading to data inconsistency, duplication, and accessibility problems.
Data governance in a data lakehouse is more structured due to the schema enforcement and indexing applied during data ingestion. This architecture allows for establishing standardized data structures and metadata as data.
They are promoting easier data cataloging and accessibility. With clearer schemas, managing data lineage, tracking data changes, and enforcing data quality standards becomes more straightforward.
Data Discovery:
Data discovery is identifying, locating, and understanding the data assets stored within a system. In both data lakehouses and data lakes, data discovery plays a pivotal role in maximizing the value of the stored data. However, the approaches may vary due to the architectural differences between the two.
Data discovery in a data lake can be complex due to the raw and unstructured nature of the stored data. Without predefined schemas and standardized metadata, finding relevant data can be challenging. Data analysts and scientists often need extensive exploration and profiling to understand the data’s contents and context. This process involves searching for keywords, examining file formats, and analyzing data patterns to extract meaningful insights.
Data discovery in a data lakehouse is more streamlined due to the schema-on-ingest approach. The applied schemas and structured metadata clearly understand the data’s structure and content during data ingestion. It makes data cataloging and searching more efficient. Users can quickly locate and comprehend the available datasets, reducing the time and effort needed for exploration.
Data Security:
Data security is a paramount concern in both data lakehouses and data lakes, as it involves safeguarding sensitive information and ensuring compliance with privacy regulations. While the core principles of data security apply to both architectures, the implementations and considerations may differ due to their distinct characteristics.
Data security in a data lake can be challenging due to the raw and diverse nature of the data. Since data is stored in its original form, it might need more standardized access controls and encryption mechanisms. Organizations must implement robust access controls, encryption, and authentication methods to protect data from unauthorized access and breaches. Data governance practices, including metadata management and data lineage tracking, are vital in maintaining security.
Data security in a data lakehouse benefits from its structured approach. Schema enforcement during data ingestion enables the application of standardized security measures, making it easier to implement consistent access controls and encryption. Security protocols can more effectively enforce predefined structures as data is ingested. Streamline data lineage tracking to enhance the ability to monitor data movement changes and aid compliance efforts.
How to choose the Right Architecture for your Big Data Needs?
Selecting the appropriate architecture for your extensive data requirements is a crucial decision directly impacting your organization’s data management and analytical capabilities. Here’s a step-by-step guide to help you make an informed choice:
Evaluate Business Objectives:
Understand your organization’s goals and data-driven objectives. Define the types of insights you seek to derive from your data to guide your architectural decision.
Analyze Data Types and Sources:
Evaluate the nature of your structured, semi-structured, or unstructured data and where it originates. This will influence the architecture’s capacity to handle different data formats.
Scalability and Performance:
Determine the scale of data growth you expect. If you wish your data to expand rapidly, architectures like data lakes and distributed databases might be more suitable for scalability.
Query and Analysis Requirements:
Consider how you plan to analyze the data. If complex queries and real-time analytics are crucial, architectures with optimized query engines, like data warehouses or data lakehouses, might be preferable.
Data Governance and Security:
Assess your organization’s data governance and security needs. A data lakehouse might be better if data quality, access controls, and compliance are paramount.
Budget and Resources:
Evaluate your budget and available resources. Some architectures require significant upfront investment, both in terms of technology and skilled personnel.
Technical Expertise:
Gauge your team’s technical expertise. Some architectures demand specialized knowledge for setup, maintenance, and troubleshooting.
Integration Capabilities:
Consider how well the chosen architecture integrates with your existing systems and tools. Seamless integration can streamline workflows and minimize disruption.
Future Flexibility:
Anticipate how your data needs might evolve. Choose an architecture that can adapt to changing requirements without significant overhauls.
Risk Mitigation:
Identify potential risks associated with the chosen architecture and have contingency plans to address unforeseen challenges.
It’s crucial to assess your organization’s specific needs and goals and adapt the transition process accordingly.
Ultimately, the exemplary architecture aligns with your business objectives, technical capabilities, and data characteristics. By carefully considering these factors and conducting thorough evaluations, you can confidently select an architecture that maximizes the value of your significant data investments.
Conclusion:
In the realm of modern data management, the comparison between data lakes and data lakehouses underscores the evolution of data architectures to meet the ever-changing needs of organizations.
Data lakes offer unparalleled flexibility, enabling diverse and unstructured data accumulation for future analysis. However, they demand meticulous data governance efforts to maximize the potential insights hidden within. On the other hand, data lakehouses strike a balance by blending the benefits of data lakes with structured querying capabilities akin to data warehouses.
Thus, this fusion streamlines data governance, accelerates data discovery, and enhances security, ultimately fostering more efficient and informed decision-making. The choice between these architectures hinges on an organization’s trade-off between flexibility and analytical performance, with data lakehouses emerging as a promising solution for those seeking a harmonious synergy between raw data storage and optimized analytics.
You may also like to read:
The Best Data Orchestration Tools that Businesses should be aware