


As an enterprise, you tend to work with a significant amount of data, especially in these modern times. Today, every person with a digital device is a data generator.
You capture the data and sort it all to form some data patterns which you can use for your enterprise.
The challenge occurs when there is too much data. New data is being generated every second, and storing this data is a challenge.
As an enterprise, you have only so much data storage capacity. Adding more storage adds up to the expenses, but you still need all that data. What is the solution?
It is deduplication and compression!
Consider you have some data that has arrived from multiple sources, but it has some common parameters. All these repeated data pointers consume some space in your storage devices.
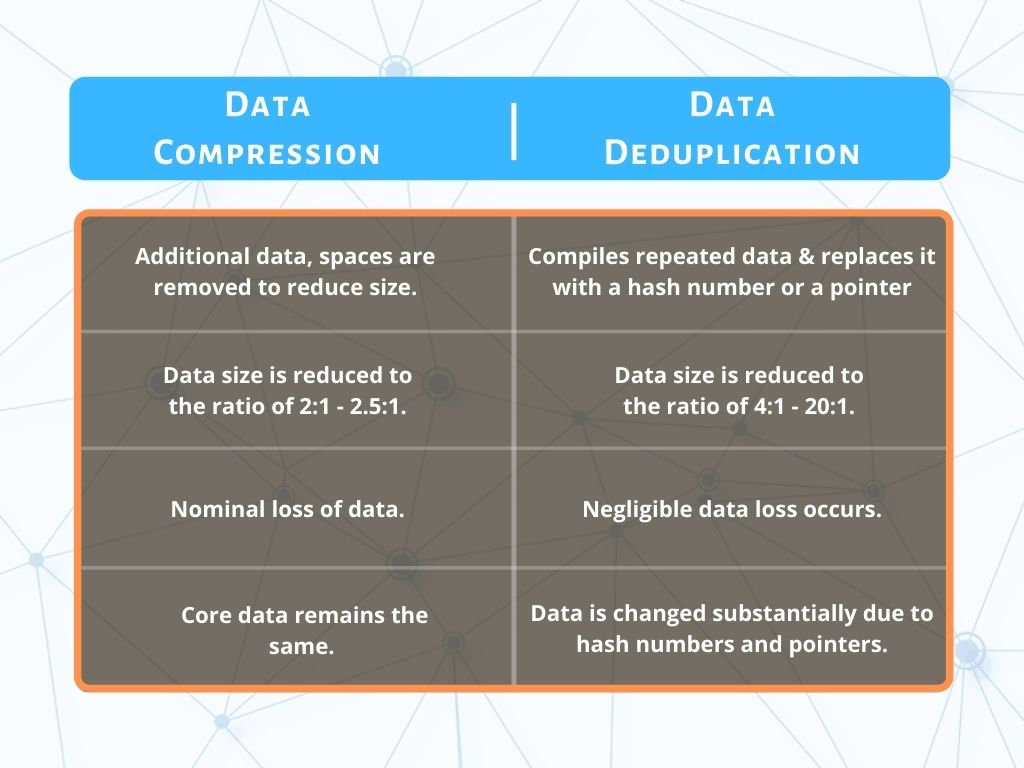
Deduplication compiles all the repeated data and replaces it with a hash number or a pointer.
Along with this, deduplication saves only one copy of the data with the hash number or pointer pointing towards the single copy.
So when you need to access the data, it can be quickly done. This also does not lose any critical information within it.
As the name suggests, compression means compacting the data so that it consumes less space.
Every data created has some supporting information on it and a lot of spaces and other allied fillers on it.
Every bit of this consumes space on the storage device. Imagine this on a ton of data that enterprises work with.
Managing all this data in its actual size is a true challenge.
Compression helps compact this data by removing the unnecessary fillers and spaces in the data. It retains vital pieces of information.
This allows enterprises to effectively store and use data without compromising on data losses.
Now that we know how deduplication and compression work, it is imperative to understand what differentiates the two. With this, we will know which works best for which enterprise.
In deduplication, the data is clustered based on the common blocks in them. A single version of each block is retained while the other occurrences hashed or referred to using pointers.
On the other hand, in compression, additional data, spaces, etc. are eliminated to reduce the data file size.
Compression claims to reduce data size to the ratio of 2:1 up to 2.5:1, as claimed by some programs based on the available data file types.
With deduplication, though, the data is altered substantially. Reduction rates can range from 4:1 up to 20:1 and with specific data types can even be reduced to 200:1.
This is subject to the data type available, and hence the same deduplication program would compress different data types with varying rates of reduction.
Deduplication involves clustering the data and keeping a single copy of the redundant data. This results in a lot of original data being eliminated, yet the core data does not change.
Hence data loss in deduplication is minimal to zero. On the other hand, in compression, excessive data is eliminated. Thus there is a loss of data involved.
Even though it does not hamper the overall integrity of data, there is an inevitable compromise involved here.
Compression removes the excessive data, but the core data package remains the same. Thus the overall data package is not changed as much.
With deduplication, though, the data is changed substantially due to hash numbers and pointers.
If the compressed data is used without the relevant software, the data will not make any sense. With compression, the data can be used as-is since the core data remains the same.
Final Word on What to Choose Between Deduplication vs Compression
Both deduplication and compression have their own set of advantages and limitations. Mostly, enterprises use the two in conjunction to derive the maximum benefit for them.
It all depends on the type of data being used that calls for which data reduction method is used. If gentle size reduction works for you, then compression is an excellent option to opt for.
In case a significant reduction is the desired output, then deduplication can help subject to the data being of a compatible format.
Also Read: How do Snapshot and Backup Differ?